 Las personas comparten un volumen increíble de contenido en el ecosistema de Facebook cada día. Facebook crea sistemas de Inteligencia Artificial que entiendan ese contenido así como el contexto que le rodea para que los individuos conecten mejor con lo que les importa y para detectar contenido inapropiado.
Las personas comparten un volumen increíble de contenido en el ecosistema de Facebook cada día. Facebook crea sistemas de Inteligencia Artificial que entiendan ese contenido así como el contexto que le rodea para que los individuos conecten mejor con lo que les importa y para detectar contenido inapropiado.
Hoy Facebook anuncia dos actualizaciones, diferentes pero relacionadas, del equipo a cargo del aprendizaje automático aplicado.
Nueva plataforma de visión computacional
· Muchas de las miles de millones de imágenes compartidas en Facebook e Instagram contienen texto, ya sean memes o, por ejemplo, fotografías de la carta de un restaurante. Para que un sistema de Inteligencia Artificial sea realmente útil necesita ser capaz de leer ese texto. Para eso es necesario el sistema de Reconocimiento Óptico de Caracteres (OCR por sus siglas en inglés), en el que Facebook empezó a trabajar en 2015.
· La escala de Facebook implica una serie de retos para OCR: el volumen de imágenes, la variedad de los idiomas (algunos escritos de derecha a izquierda, otros con muy pocos datos de entrenamiento disponibles, fuentes, creatividades, etc.). Además hay que añadir la eficiencia necesaria para procesar toda esta cantidad de imágenes y actuar rápidamente.
· Para dar respuesta a estas necesidades específicas, Facebook desarrolló y desplegó un sistema de aprendizaje automático a gran escala, Rosetta, que extrae textos de miles de millones de imágenes y fotogramas de vídeo. Este proceso lo realiza en una amplia variedad de idiomas cada día y en tiempo real.
· Rosetta se está utilizando ya por equipos de Facebook e Instagram. Está ayudando a mejorar la relevancia y la calidad de las búsquedas de imágenes, detectando proactivamente discurso de odio en distintos idiomas, y mejorando la capacidad de la plataforma para hacer emerger contenido personalizado en News Feed.
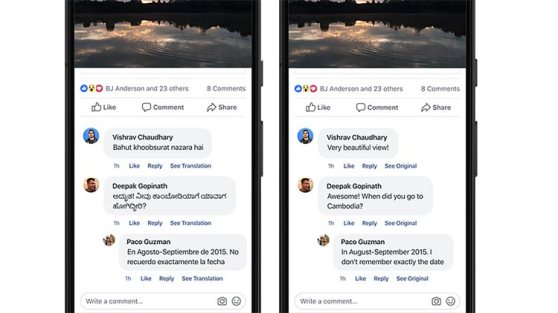
Facebook añade 24 nuevos idiomas a sus traducciones basadas en Inteligencia Artificial
· En Facebook empleamos una traducción automática neural para ofrecer este servicio a nuestra escala. Hasta hace poco, los desafíos técnicos nos impedían aumentar el número de idiomas en que damos servicio. Un desafío era obtener datos paralelos para algunos idiomas, y otro encontrar una forma de entrenar a los sistemas lo suficientemente rápido para producir traducciones válidas en poco tiempo.
· En el post se detallan las tres estrategias que se han seguido para superar estos dos desafíos: aumentando el etiquetado en el dominio, utilizando métodos semi-supervisados y utilizando modelado monolingüe.
· Ahora Facebook realiza traducciones a más de 125 idiomas y 4.504 dialectos. Esto incluye hausa, nepalí, urdu y muchos otros. Es un aumento de 2.1 puntos sobre el número de dialectos que se traducían en enero de 2018. No son traducciones perfectas pero son un paso importante para limitar las barreras idiomáticas.
